Googleが、人が話した内容を本人の声のまま音声翻訳してくれるTranslatotronを発表した。音声翻訳の未来を切り開くものになる。
音声翻訳の仕組み
例えば洋画の吹き替え版を作ることを考えてみる。
まず、その洋画のセリフを全て書き起こし、その文章を自然な日本語になるよう翻訳して台本を作り、日本語版を担当する声優に読んでもらうということになる。
これまでの音声翻訳でも同様に、まず話した内容が自動音声認識により文章として書き起こされ、そこから機械翻訳を通して音声出力を行うという形が採られていた。
音声-テキスト-音声という異なる翻訳方法を組み合わせた「カスケードモデル」が従来の方法だったのに対し、Translatotronは最初から最後まで音声翻訳で完結するというend-to-endの手法が採られているのが特徴。
途中で文章にするというステップがない分、シンプルなので従来の方法よりも迅速な翻訳が行える。
Google AI Blogに「 Introducing Translatotron: An End-to-End Speech-to-Speech Translation Mode」という記事が掲載されている。
Translatotronは1つの言語から別の言語へ、音声を直接翻訳する初めての人工知能モデル。
さらにTranslatotronは翻訳後の音声で、もともとの話者と同じ声を使うこともできる。
機械翻訳の品質評価法であるBLEUスコアはTranslatotronは従来のカスケードシステムよりも少し低いが、カスケードモデルの翻訳の基準値以上の正確性は持っている。
Translatotronのメカニズム
機械翻訳のend-to-endモデルは2016年の論文 (「Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation」)で初めて発表され、それ以来、研究が続けられてき。
end-to-endのモデルはカスケードモデルよりも優れているということが2017年に実証された。
Translatotronはスペクトログラム (声を周波数・振幅分布・時間の三次元で表示したもの) の情報を入力として受け取り、変換したい言語の音声をスペクトログラムとして生み出すSequence to Sequenceのネットワークを基礎としている。
スペクトログラムをタイムドメイン (信号からその周波数成分だけではなく時間軸上の波形も忠実に再現したもの) の波形に変えるというNeural Vocoderを使用している。
さらに話者の音声を維持して翻訳後の音声を合成するSpeaker Encoder も採用されている。
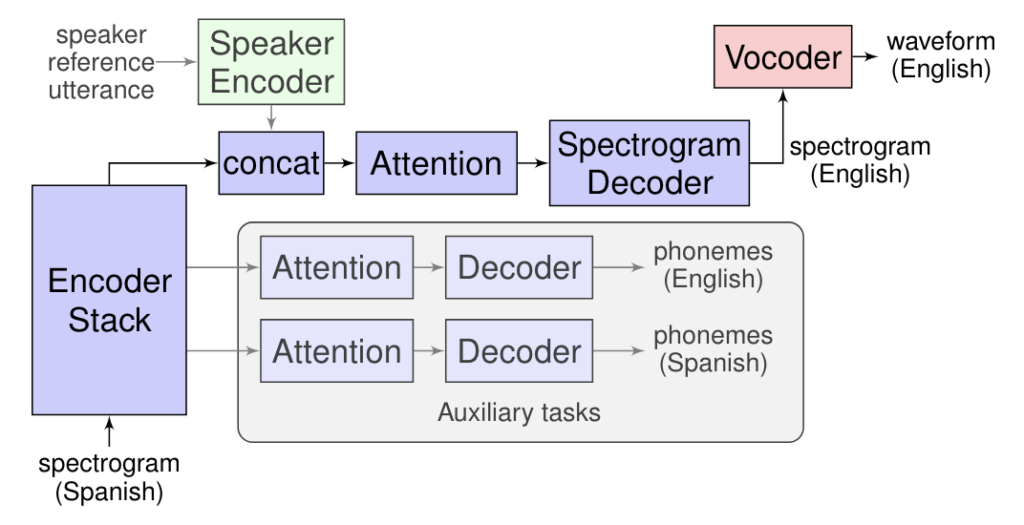
Source: https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html
音声翻訳の実際の様子
Translatotronによる実際の音声翻訳の様子は以下から確認できる。
オリジナルのスペイン語の音声
話者の声を維持したままTranslatotronで英語に翻訳したもの
ここからTranslatotronの音声翻訳を聞くことができる。
まるでドラえもんに出てくる、未来の「ほんやくコンニャク」のようだ。
追記
Googleは同様のシステムを使って肺がん検診をより正確に判定できる人工知能を作成している。