近年のオミクス解析技術や顕微鏡技術の進展により、爆発的に膨大な細胞データを得られるようになりました。人工知能(AI)・機械学習の隆盛と相まって、「AI Virtual Cell(AIVC)」、すなわち「多層的な生物学データから直接学習することで、細胞そのものを仮想的に再現・操作できるAIモデルを構築しよう」というビジョンが提唱されています (Cell, 2012)。この記事にまとめていきます。
この記事の内容
AI Virtual Cell(AIVC)の概要と背景
従来の細胞モデルや数理モデルの多くは、微分方程式や確率過程、あるいはエージェントベースモデルを活用し、特定の細胞機能やプロセスだけを切り出して解析するものでした (Nature Reviews Genetics, 2019)。こうしたモデルは、ある生化学反応経路やシグナル伝達ネットワークに焦点を当てることには向いていますが、細胞全体像を系統的に学習し、さらに予測やシミュレーションを幅広く展開するには限界があります。
一方、AIを用いたデータドリブンアプローチでは、膨大な実験データを学習することで、人間が手動で書き下すルールベースでは捉えきれないスケールや複雑性をそのまま内包したモデルを作成できます 。2024年のノーベル化学賞をとったAlphaFoldを筆頭とする三次元構造予測や、タンパク質間相互作用・リガンド結合などにおける深層学習の成功例は、その可能性を十分に示しています。AIVCのビジョンは、“細胞の状態”を分子~細胞~組織スケールで学習するような巨大モデルを作り上げることで、細胞を高度にシミュレーションできるようにする、という壮大な構想です (Trends in Cell Biology, 2003)。
AIVCに求められる3つの中核的機能
AIVCが備えるべき能力として、(1) ユニバーサル表現、(2) 細胞機能・動態の予測、(3) in silico 実験の3つがあげられます (Cell, 2012)。これらは従来の細胞モデルにはなかった、あるいは限定的だったポイントを大きく拡張するものです。
ユニバーサル表現(Universal Representation)
ユニバーサル表現とは、分子・細胞・組織という複数スケールにまたがるデータを一つの空間(embedding)に写像し、互いに比較・補完可能な形で取り扱えるようにする枠組みを指します (Nature Biotechnology, 2024)。
従来のゲノム配列、トランスクリプトームやプロテオーム、構造画像、空間オミクスなどは、それぞれ異なる形式や解像度で細胞を捉えます。AIVCでは、これらを一元的に統合し、ある細胞状態を多面的に表現するベクトル表現(embedding)へマッピングすることを狙います (eLife, 2017)。
このユニバーサル表現の大きな利点として、未観測の状態へも一般化する能力が挙げられます。例えば、AIVCがマクロファージにおける炎症応答を学習していれば、微小グリア細胞において似た炎症状態が生じた場合にも、その挙動をある程度予測できる可能性があるのです。これは従来の個別モデルでは困難だった「未観測の細胞状態への外挿」を実現し得る重要要素です (Nature Biotechnology, 2024)。
細胞機能・動態の予測
AIVCの中心的な応用例として、「特定の細胞がある刺激や擾乱を受けた際、どのように変化するか」を予測する能力が挙げられます (Nature Methods, 2023)。例えば、遺伝子変異・薬剤・物理的ストレス・感染など、多様な条件下で細胞がどのように反応し、最終的にどんな転写・翻訳・代謝状態に至るのかをシミュレートするわけです。
そのためには、大量の介入実験データが不可欠であり、CRISPRスクリーニングやドラッグスクリーニング、RNAi法によるノックダウンなど、マルチモーダルかつ包括的なデータセットの構築が求められます (Cell, 2016)。これらを学習することで、AIVCは単に静的な「スナップショット」を超えて時間的な変化(ダイナミクス)まで扱えるようになるのです。
また、AIVCは分子スケールから細胞スケール、さらには組織スケールへと階層を跨いで予測を行うことを目指します。これにより、特定のタンパク質修飾や転写因子活性の変化が組織レベルの表現型にどう影響するか、といった総合的なシミュレーションが可能になると期待されています (Science, 2021)。
実験とデータ生成のガイド
3つ目の重要な機能は、AIVCを「仮想実験装置」として利用し、新たな実験仮説の生成や実験計画の自動化を促進することです (Nature Communications, 2023)。これは2つの面で画期的です。1つはラボで実施が難しい条件や組み合わせを仮想で試すという点。例えば、非常に複雑な多重遺伝子ノックアウトや組み合わせ薬剤投与など、物理的・コスト的に制限がある実験をin silicoでスクリーニングし、有望な候補だけを絞り込んで実験することで、大幅な効率化を図ることができます。
もう1つは、自己学習的なデータ生成ガイドとしての点。AIVCは自身の予測に不確実性スコアを付与し、まだ知識が乏しい領域や誤差が大きい領域を特定して、「この条件を追加で測定すると仮説が明確化する」「この細胞系でのデータを取るとモデル精度が高まる」といった実験デザインを提案します (bioRxiv , 2023)。いわゆるアクティブラーニングやベイズ最適化の概念を生物学に応用した新しい形の「ラボ・イン・ザ・ループ」手法となる可能性を秘めています。
AIVCを構築するための階層的アーキテクチャ
AIVCを実装する上で鍵になるのが、「分子→細胞→多細胞(組織)」の3つの物理スケールに対応する階層を、いかに統合的に学習させるかです (Nature Methods, 2024)。そのための基本概念として Universal Representation (UR) と Virtual Instruments (VIs) の2つが提案されている。
Universal Representation (UR)
URとは、多種類のマルチモーダルデータを連結・埋め込み、一定のベクトル表現として保持できる「基盤モデル (foundation model)」です (Nature Methods, 2024)。具体的には、以下の3つのスケールでそれぞれURが定義されます。
- 分子スケールUR: DNA・RNA・タンパク質や代謝物などを原子レベル、もしくは一次配列や立体構造として表現する。すでにAlphaFoldのように配列から三次元構造を推定するモデルが存在し、多言語モデルのように配列情報を「文字列トークン」として扱う試みが広がっています (Nature, 2021)。
- 細胞スケールUR: 1.の分子表現を集積し、それぞれの時空間的配置や量的情報を組み合わせて「細胞としての総合的状態」を表す。たとえば単一細胞RNA-seqやイメージングデータ、空間プロテオミクスなどを併せて「この細胞はどのようなトランスクリプトームと形態を持ち、どう振る舞っているか」を学習させます 。
- 多細胞スケールUR: 細胞同士の相互作用や組織構造を、空間的な配置やシグナル伝達ネットワークとして捉え、組織・オルガン・あるいは個体レベルでの多細胞系の状態を記述。スライド画像による組織構造、空間的トランスクリプトーム、細胞間相互作用のグラフ構造などを統合して一貫した表現を構築します (Nature Biotechnology, 2022)。
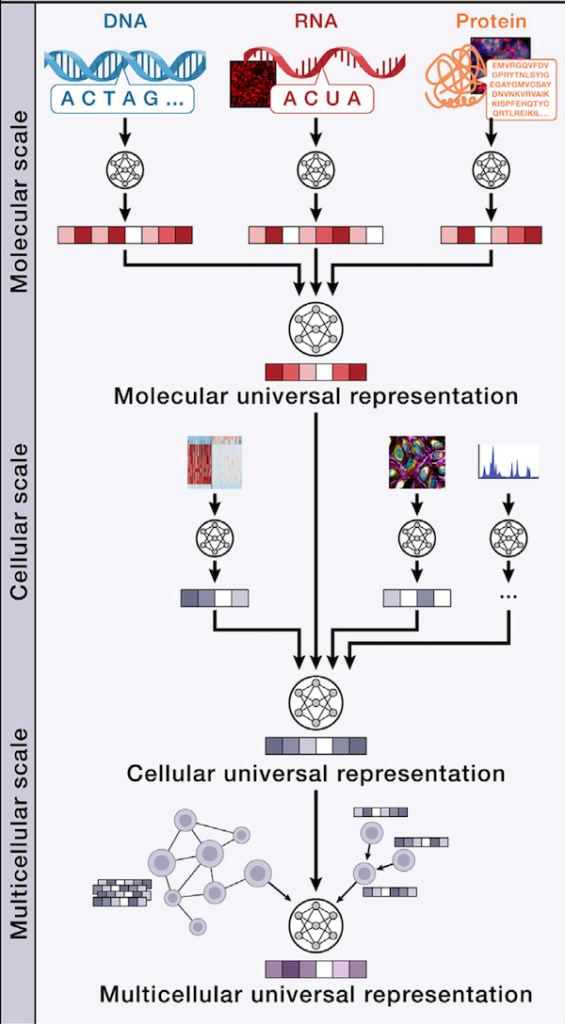
Bunne et al., Cell 2024より引用
Virtual Instruments (VIs)
VIsはURを入力として、特定の出力や操作を行うためのニューラルネット群を指します。2種類に大別されます。
- Decoder VI: URを入力にしてヒトが解釈できるアウトプットを生成するモジュール。たとえば「細胞の画像を再構成する」「遺伝子発現パターンを予測する」「細胞種ラベルを出力する」「タンパク質構造モデルを可視化する」などが該当します (Frontiers in Cell and Developmental Biology, 2023)。
- Manipulator VI: URを入力にし、何らかの操作(擾乱)を加えて、変化後のURを出力するモジュール。例えば「遺伝子Xをノックアウトしたら、この細胞URはどう変化するか」「薬剤Yを加えたら、細胞周期や転写状態はどうなるか」をシミュレートする際に用いられます (Nature Biotechnology, 2023)。
分子URを操作するManipulator VIでは、「特定のアミノ酸変異によるタンパク質構造変化」などを予測できます。細胞スケールだと「あるがんドライバー変異を導入したら、表現型はどう変わるか」、多細胞スケールだと「免疫細胞との相互作用が増えた場合に腫瘍内微小環境はどう再編されるか」など、多彩な生物学的操作に対応可能です (Nature Methods, 2024)。
このURとVIの組み合わせが、AIVCの柔軟性と拡張性を支えるベースの仕組みになります。たとえば、あるURが学習済みの状態に対して、新規のDecoder VIやManipulator VIを「プラグイン」のように追加し、目的に応じた機能をどんどん拡張していくことができるからです (Nature Biotechnology, 2023)。
AIVCに必要な多階層データとその取得
AIVCを構築するにあたっては、「いかに大規模で多様なデータを集積し、体系的に学習に投入できるか」が極めて重要とされます。以下の視点が大事とされています (Nature Reviews Genetics, 2022)。
- 分子スケール: 遺伝子配列、RNA配列、タンパク質配列などのビッグデータや、構造生物学データ(X線結晶構造解析、NMR、Cryo-EMなど)、原子レベルシミュレーションデータ。これらを総合することで、タンパク質間相互作用や配列-機能相関を一括学習する (Nature, 2021)。
- 細胞スケール: 単一細胞レベルのトランスクリプトーム・エピゲノム・プロテオーム・メタボロームデータに加え、ライブセルイメージングによる時間的変化データ、細胞内構造の超解像顕微鏡画像など (Nature Biotechnology, 2024)。
- 多細胞・組織スケール: 組織切片の空間トランスクリプトームや多重免疫染色画像、組織の3D断層画像、疾患組織と正常組織の比較データなど (Nature Methods, 2022)。
- 介入・擾乱データ(Perturbation): 遺伝子ノックアウト・ノックダウン・薬剤スクリーニングなどの実験条件下で得られるシングルセル解析データや顕微鏡画像、または複数の遺伝子や薬剤の組み合わせ (Nature Methods, 2023)。これらが多ければ多いほど、モデルが介入の因果的効果を学習しやすくなります。
ヒトやマウスなどのモデル生物に偏るデータバイアスをいかに緩和するか、あるいは遺伝的多様性をいかにカバーするかといった点も重要です (Nature, 2021)。AIモデルは学習データの分布に強く依存し、偏ったデータでは特定の系や特定の集団にしか適用できないモデルになってしまう恐れがあります。
特に医学領域への応用を視野に入れれば、人種的・地理的多様性を含む多元的なゲノムデータや表現型データが必要です。一方で、プライバシー保護や倫理的観点からデータ共有には制限があり得るため、分散学習などの技術開発も考えられます (Nature Methods, 2022)。
モデル評価と信頼性の確立
AIVCの性能をどう評価し、どのように「このモデルは信頼できる」と言えるようにするかは重要なテーマです。単に教師データに対する再現率や汎化精度だけでは、生物学的にどの程度モデルが本質的メカニズムを学習しているのか判断しにくい場合があります (Science, 2012)。
そこで、複数モーダルの整合性確認(クロスモーダルな再現度)や、未観測状態への外挿性能などが評価指標として提案されています (Nature Methods, 2024)。例として、mRNA発現量からタンパク質局在や形態変化をどの程度予測できるか、あるいは別の細胞型や組織でも転移学習が通用するか、といった評価が考えられます。
もう一つの評価軸は、新たなバイオロジーの発見にどれだけ役立ったかという観点です。単に予測性能が良いだけでなく、AIVCを活用した結果、実験的に検証可能な具体的仮説が提示され、それが実験によって確認されることで生物学の理解が進展する。これがAIVCの最大の意義とされます (Nature Methods, 2024)。
深層学習モデルはしばしば「ブラックボックス」と呼ばれますが、AIVCのように医学生物学に用いる以上、最低限の解釈性や因果的整合性が求められることは言うまでもありません (Science, 2021)。
具体的には、モデルが予測を行う際に「どの分子経路やタンパク質間相互作用が鍵となったか」を可視化する技術や、反事実的なシミュレーション(仮に遺伝子Xが存在しなかったらどうなるか、など)によって仮説を生み出す仕組みも研究されています (Nature Methods, 2024)。モデル構造自体に因果モジュールを組み込むアプローチや、入力特徴量に対する感度解析を行うアプローチなど、多彩な戦略が探求中です。
AIVCがもたらす応用分野の広がり
フェノタイプ指向の創薬・再生医療
従来の創薬は分子ターゲットごとのスクリーニングから始まることが多く、一方でフェノタイプスクリーニング(細胞レベルの表現型変化を直接捉える手法)が再注目されています (Nature Genetics, 2015)。AIVCは、細胞全体を仮想的に再現するため、特定の遺伝子や経路だけでなく「細胞が示す形態学的・機能的変化」を横断的に捉えられます。
また、細胞治療(CAR-TやiPS細胞を用いた再生医療)では、患者ごとの細胞特性を考慮した精密なデザインが求められます。AIVCを用いることで、個々の患者の細胞状態を仮想的に再現し、遺伝子改変や培養条件を最適化できる可能性があります (Science Translational Medicine, 2013)。
がん研究と空間生物学
がんにおける腫瘍微小環境(TME)は、がん細胞と免疫細胞、線維芽細胞など多種多様な細胞が相互作用する複雑な場です。そこでは空間的配置が治療反応や免疫回避に大きく影響するため、空間オミクス技術が急速に発展しています。
AIVCの多細胞スケールURとManipulator VIを組み合わせれば、「腫瘍細胞の特定遺伝子変異が周囲の免疫細胞の局在や活性にどう影響するか」を仮想的に再現し、効果的な免疫療法標的や薬剤組み合わせを探索できるかもしれません (Nature Reviews Clinical Oncology, 2022)。がん免疫研究において、アプローチが生体内状況の近似度を大きく高めると期待されます。
患者個別のデジタルツインと予防・先制医療
「患者ごとに仮想細胞モデルを作り、病態や治療反応を事前にシミュレーションする」というデジタルツインの発想も、AIVCによって一層実現性が高まります (npj Digital Medicine, 2024)。具体例として、慢性疾患の患者の経時的な細胞状態変化をモニタリングし、バイオマーカーの変動を加味しながら、将来的な増悪リスクや治療反応を予測できるかもしれません。
さらに、血液検体からのシングルセル解析や液体生検のデータをAIVCに統合することで、難組織(たとえば脳や膵臓など)への非侵襲的な推定を行うモデル構築も考えられます (Cancer discovery, 2021)。こうしたモデルは、複数の生体情報を組み合わせた統合的診断の道を開く可能性があります。
新しい科学的アプローチ:仮説フリーの発見
AIVCは膨大なデータから学習しているため、人間が思いつきもしないような因果的な仮説やネットワーク構造を示唆することが期待されます (Science, 2021)。これは「仮説駆動型研究」から「データ駆動型研究」へと移行する流れを一層加速させる要因にもなります。AIVCを使って大規模な組み合わせ実験をin silicoで行い、その出力をもとに新しい仮説を得る、いわゆる「自己駆動型研究」の可能性も言及されています (Nature Methods, 2024)。優先度が高い検証実験を絞り込み、高次の複雑な生物学的相互作用を発見するプロセスが、今後のバイオサイエンスの主要な手法になるかもしれません。